
Do you remember when we used to have multiple steps of Natural Language Processing (NLP) specific tasks and try out dozens of methods only for text classification?
Yeah, since 2021 that became quite obsolete, and Large Language Models created a real momentum in the NLP words. Today, to perform a natural language-related task, you may only need to know how to speak English and have enough money to pay for a model. It may seem quite easy and you may think, oh I can create whatever I want in a few minutes. Unfortunately no, we have a plethora of LLMs that can perform the same tasks, but to get the best out of these models you will need much more than just simple prompting and a few dollars.
In this story, I will give you a practical guide on how to choose the suitable LLMs for your use case, which aspects are crucial to consider, and which parameters you should privilege.
Sidenote: If you are not a machine learning expert and would like to pick the right model for your use case, we offer you a free implementation plan for AI products (including model and cost report) that you can directly give to any company to implement your solution. Head to launchpad.ulife.ai/free-report to describe your use case and you will receive an implementation plan drafted by an AI expert for free. Hurry up, we will close it soon.
LLMs – Introduction
Large language models became popular after the release of ChatGPT in November 2022, but before that LLMs were around and could do nearly the same things. The only thing that changed was the use case applied to these LLMs. LLM or Large language model is a deep learning model (generally based on transformers) that has been trained on a really large set of data and has created a sense of understanding of natural languages. The end model could be easily repurposed for many NLP tasks including Chatbots, Text classification, Text summarization, and much more. If you are wondering how LLM could understand natural language only with the training process, this guide from Stephen Wolfram is a lovely start. You will understand the learning process of LLMs in-depth and gain more knowledge about the intelligence of LLMs. With that said, we have two big categories when it comes to choosing your LLMs for any use case. We can consider close source models including big players like Google, OpenAI, Anthropic, Cohere, and much more. We also have open source models including LLama from Meta (formerly Facebook), Mistral, QWEN from Alibaba, Gemma from Google, Microsoft(with Phi), and hundreds of developers pushing forward to make these models more and more perfomant.
Close vs Open battle
Let’s first explain what is the difference between close-source and open-source models (and why you need to be extremely cautious when it comes to licences).
In the context of Large Language Models (LLMs), “Closed” and “Open” models refer to the accessibility and control over the model’s architecture, training data, and codebase:
Closed Models:
- Proprietary: Closed models are typically owned and controlled by a single organization. The model’s code, training data, and internal workings are not publicly accessible.
- Limited Access: You interact with these models through APIs or specific platforms, without the ability to modify or examine the model’s inner workings.
- Examples: OpenAI’s GPT-4 and Anthropic’s Claude, where only the outputs are accessible through an API, not the model itself.
- Pricing:
- Subscription or Usage-Based: Access to closed models is often provided through a subscription or a pay-per-use pricing model. You are charged based on the number of API calls, token usage, or the level of service (e.g., standard vs. premium).
- Enterprise Licensing: Some providers offer enterprise-level licensing for businesses, which can include custom pricing based on usage, more privacy, additional support, or dedicated instances (Like instances of GPT hosted by Azure).
- Cost:
- Ongoing Costs: You incur ongoing costs as you continue to use the model. Costs can scale quickly with heavy usage, especially in commercial applications.
- Examples: OpenAI’s GPT-4 API has a tiered pricing structure based on the number of tokens processed. Prices might range from fractions of a cent per token to higher rates for better models.
Open-source Models:
- Open Source: Open models have their code, architecture, and sometimes even the training data publicly available. This allows anyone to inspect, modify, and deploy the model independently.
- Community Contributions: Open models often benefit from contributions by the community, including improvements, optimizations, and adaptations for specific use cases.
- Examples: Models like Meta’s LLaMA (Large Language Model Meta AI) and Google Gemma are open models where the code and, in some cases, the weights are available for public use.
- Pricing:
- Free or One-Time Costs: Open models are often available for free, though there may be costs associated with downloading large models or datasets. Some open models might be released under licenses that allow commercial use without additional fees.
- Infrastructure Costs: Although the models themselves might be free, you bear the cost of infrastructure needed to run these models, such as cloud computing resources or on-premise hardware.
- Cost:
- Initial Setup and Maintenance: You may face higher initial costs for setting up the infrastructure to host and run the model. Maintenance, updates, and optimizations are also your responsibility.
- Examples: Running a large open-source model like Meta’s LLaMA might require significant cloud computing resources, which can become expensive, especially if scaling for commercial use.
These aspects determine the first and most crucial choice you have to make for your application. Alongside this choice, you still have multiple parameters to consider to make an informed choice.
Choose wisely
Choosing a model is an important step when we talk about LLMs and their applications. You can mitigate the risk by using wrapper libraries like LangChain to be able to easily change the model provider later, but you will still have model-specific code and infrastructure costs in some cases to support.
There are many aspects you need to consider while choosing A large language model including:
Creativity
When dealing with a use case where creativity is a big deal, It may seem like a single parameter (temperature parameter) that you can tweak to get more creativity from your model but it is more complex than that.
Creativity is defined by your model’s capability to create new pieces of content that follow the instructions it has been given. For example, if you create an app that will create stories for children you may want to choose a model that can craft realistic stories tailored to the specific audience it has been given to.
Quick important note, this factor is limited in private models because of the censorship applied to these models. It becomes hard for them to talk about certain topics which gives them less window for possibilities. Fortunately for you, there is a kind person on the internet who created a page ranking model by creativity. You may take a look here: https://huggingface.co/datasets/froggeric/creativity
As of September 2024, the ranking was the following:
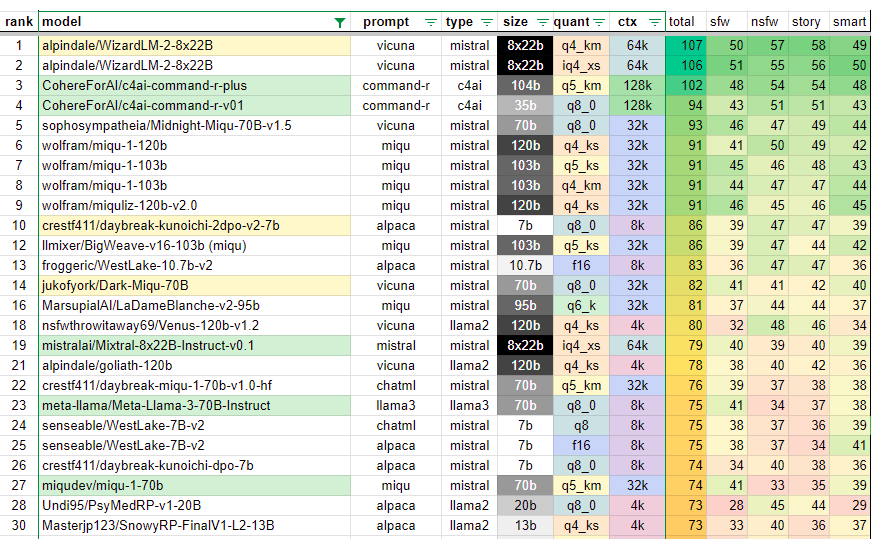
The best way to test it is of course to play around with these models with your use case in a playground environment and see the most creative.
Instruction following capabilities
Prompting is a huge advancement for Natural Language Processing, but all its values exist as long as the model can follow your prompt extremely well. Instruction-following capabilities ensure that your model can follow your instructions carefully and in some cases avoid tricks that are designed to deviate the model from its initial instructions.
To be honest, despite multiple benchmarks of LLM Instruction following capabilities, to be able to ensure that your model follows strict instructions, you still need to test in a playground with multiple variations of your prompt.
Function calling capabilities
Function calling capabilities are particularly important in scenarios where the LLM needs to interface with other software or APIs. For example, you may need your LLM to communicate with your internal database, or to write its result in a file… Anything that makes the Large Language Model interact with the external world is bound to function calling. For that, the model needs to detect when it should respond and when it should get data from your external system, which is not a trivial task considering the ambiguity of human languages.
University of California, Berkeley released an interesting leaderboard ranking LLMs by their function-calling capabilities.
https://gorilla.cs.berkeley.edu/leaderboard.html
As of the date of publication of this story, the leaderboard is the following:
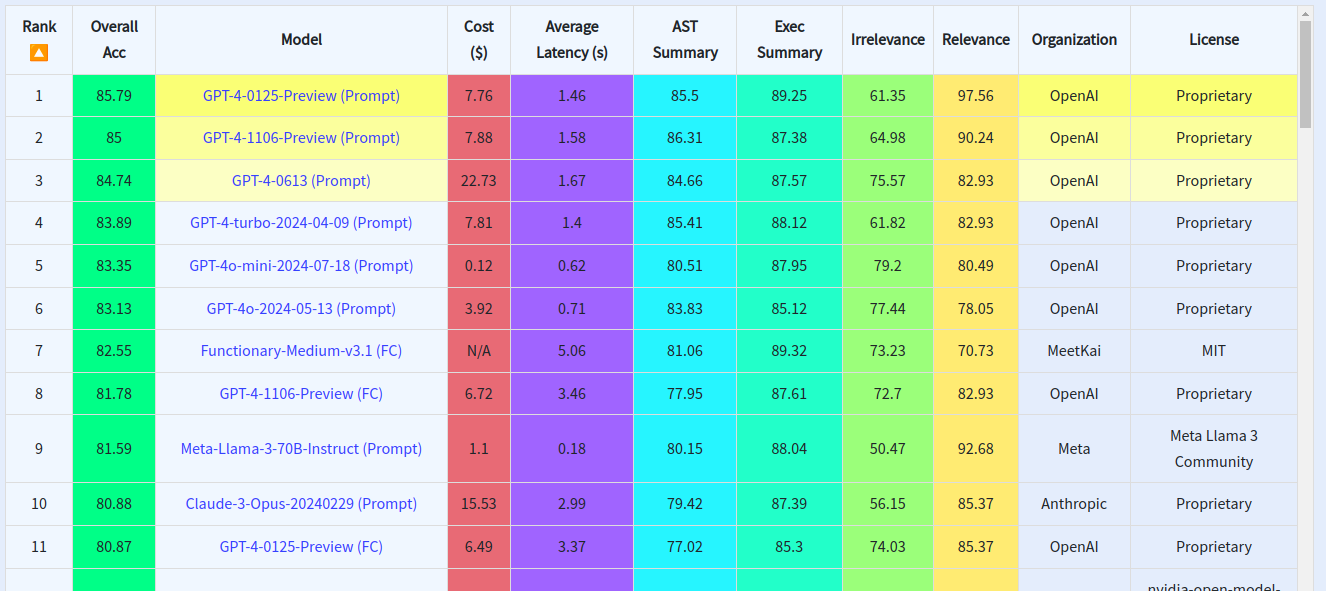
Quick side note
If you want key metrics concerning your AI use case but not the overhead that comes with it, we have built the perfect site for you. You can go ahead and visit http://launchpad.ulife.ai/free-report describe your use case and you will get a detailed implementation plan and the suitable LLM model for your use case. It usually costs around 2000$ but we recently opened a free tier for your first project. Go ahead and try it out for free (it may not be free for a long time 🙂).
Pricing
When it comes to pricing, we can’t have a single winner but many tradeoffs. It’s essential to consider both the immediate and long-term costs associated with the model. For closed models, pricing typically revolves around a usage-based or subscription model, where costs can accumulate quickly depending on the frequency of use and the complexity of the tasks. This pricing structure is predictable but can become expensive for high-volume applications, making it suitable for those who prioritize ease of use and immediate deployment without the need for extensive infrastructure. On the other hand, open models might come with lower or no direct fees but require significant investment in infrastructure, including cloud computing resources on-premise servers, and ongoing maintenance. When choosing an LLM, you should consider the total cost of ownership, which includes the model’s usage costs, infrastructure requirements, scalability, and the ability to customize or fine-tune the model according to specific needs. Balancing these factors against the expected return on investment (ROI) is crucial in determining the most cost-effective solution for the organization’s goals.
Latency
Concerning Latency, there are mainly two possibilities. If you want to have extreme control over your model latency, you should choose an open-source model. In that case, you will be able to increase your infrastructure and make it faster or use solutions like Groq to make your inference faster. For real-time call agents use cases, for example, latency is crucial and should be a defining factor while choosing the model. On the other hand, when you choose a close source model, you can not make your instance faster. you can only rely on the provider’s ability to improve their speed whenever they can, which makes them not flexible.
Privacy (Self-hosted/private) and Legislation (EU laws for example)
When considering a Large Language Model (LLM) concerning privacy and legislation, especially within stringent regulatory environments like the European Union (EU), it’s crucial to weigh the implications of data handling and compliance. Self-hosted or private LLMs offer significant advantages in terms of privacy, as they allow you to keep data in-house, minimizing the risk of exposure to third-party providers.
This is particularly important for sensitive industries where data privacy is paramount, such as healthcare or finance. Self-hosting also provides greater control over data processing and storage, making it easier to comply with strict data protection laws like the General Data Protection Regulation (GDPR) in the EU.
On the other hand, closed models managed by third parties like OpanAi or Google might pose challenges in meeting these legal requirements, as they often involve data being processed outside the organization’s direct control, potentially even in different jurisdictions.
When choosing an LLM, you must consider your compliance obligations, the sensitivity of the data being processed, and the potential legal risks associated with data breaches or non-compliance.
Practical example: Choosing the Right LLM for a Financial Advisor AI App
Let’s consider that we are a company with enough budget (a neo-bank for example) and we want to choose a suitable LLM for a Financial Advisor AI App. You will consider all the aspects introduced previously and choose wisely our model. First here is a summary table of what to expect for each aspect concerning our use case.
Comparative Table of Factors to Consider
| Factor | Description | Open-Source Models | Closed-Source Models |
|---|---|---|---|
| Creativity | Ability to generate unique and imaginative responses. | Generally less restrictive, but may require tuning. | Often more consistent but may be limited by built-in content filters. |
| Instruction Following | Accuracy in understanding and following detailed prompts and instructions. | Varies by model; may require fine-tuning. | Typically strong, with ongoing updates improving performance. |
| Function Calling | Capability to interact with external systems, APIs, or databases. | Requires custom development; models like Gorilla excel here. | Often integrated, but flexibility is model-dependent. |
| Accuracy | General correctness and reliability of responses. | Varies; fine-tuning can improve results. | Typically higher out-of-the-box accuracy. |
| Pricing | Cost-effectiveness considering usage and infrastructure costs. | Lower direct costs but higher infrastructure investment. | Predictable but potentially expensive for high-volume use. |
| Latency | The response time of the model is crucial for real-time applications. | Controllable with self-hosting and optimized infrastructure. | Dependent on the provider’s infrastructure; less customizable. |
| Privacy & Legislation | Compliance with data protection laws (e.g., GDPR) and the ability to keep data in-house. | High control over data; easier to comply with regulations. | Potential issues with data sovereignty and privacy. |
Let’s suppose we have to choose between ChatGPT, LLAMA, MIstral, Phi, Gemma, Gemini, and Qwen, … You may add as much as we want. This table should be your decision panel. Let’s create an overview of each model’s strengths and weaknesses based on our use case:
Comparative Table of LLMs
| Model | Creativity | Instruction Following | Function Calling | Accuracy | Pricing | Latency | Privacy & Legislation | Strengths | Weaknesses |
|---|---|---|---|---|---|---|---|---|---|
| ChatGPT (OpenAI) | High | Excellent | Integrated | High | Subscription-based | Moderate | Third-party hosted; GDPR compliant but limited control | Strong general-purpose model with robust API support | Higher cost for high-volume usage; limited customization |
| LLAMA (Meta) | Moderate | Good | Limited | Moderate | Open-source, infrastructure costs | Variable | Self-hosted; full control over data | High customizability and privacy | Requires significant setup and tuning; moderate instruction following |
| Mistral | High | Good | Moderate | High | Open-source, infrastructure costs | Variable | Self-hosted; full control over data | Strong creative capabilities and flexible deployment | Less polished API integration |
| Phi | Moderate | Excellent | Strong | High | Subscription-based | Low | Third-party hosted; less control over data | Very strong in following instructions and API calls | Expensive; limited data control |
| Gemma | Moderate | Good | Moderate | High | Open-source, infrastructure costs | Variable | Self-hosted; full control over data | Reliable accuracy and self-hosting | Setup complexity and tuning required |
| Gemini | High | Excellent | Strong | High | Subscription-based | Moderate | Third-party hosted; GDPR compliant but limited control | Balanced in creativity and accuracy, strong API support | Costs can escalate; limited customization |
| Qwen | High | Good | Moderate | High | Open-source, infrastructure costs | Variable | Self-hosted; full control over data | Flexible and good for privacy-conscious applications | Requires significant technical expertise |
As a financial advisor chatbot is extremely sensitive in terms of privacy, we first emphasize the privacy column. But alongside that factor, we also need accuracy because the model should not fool the users. Taking these into account, as we have the budget for our project, we will go with a fine-tuned version of Qwen (Which is as of date the best-performing LLM) and keep our user’s data private.
Conclusion
In conclusion, choosing the right LLM for your project requires careful consideration of various factors, including privacy, accuracy, and specific use case requirements. For those interested in exploring the power of AI, we have built a frontend AI assistant that codes all your projects frontend for you.. You can register for early access here. And for those who want a custom AI solution, head to ulife.ai and get a free consultation call.
Leave a Reply